
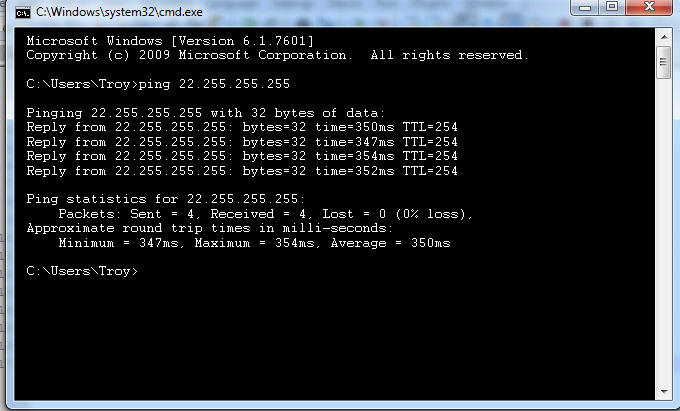
 Recently I was inside a Brigade’s NETOPS cell spending some time talking to the JNN team. They had “established” three HCLOS links to their BNs but as I proved a few times, weren’t actually routing over them. We were talking more about the HCLOS links and I asked the operator to go ahead and try pinging the remote CPN. When the operator issued the ping command, he saw something similar to the results here. Me and the local CECOM guy stationed here looked at each other and let out a little laugh and then proceeded to ask the operator what was wrong with the results that we saw. After letting the operators stumble around a little bit, (they didn’t see it), I pointed out that it appeared that we had a case of asymmetric routing occurring.
Recently I was inside a Brigade’s NETOPS cell spending some time talking to the JNN team. They had “established” three HCLOS links to their BNs but as I proved a few times, weren’t actually routing over them. We were talking more about the HCLOS links and I asked the operator to go ahead and try pinging the remote CPN. When the operator issued the ping command, he saw something similar to the results here. Me and the local CECOM guy stationed here looked at each other and let out a little laugh and then proceeded to ask the operator what was wrong with the results that we saw. After letting the operators stumble around a little bit, (they didn’t see it), I pointed out that it appeared that we had a case of asymmetric routing occurring.
We went into both of the routers involved in the link and sure enough one had an OSPF cost of 100 and the other had a cost of like 600. I thought this was a little odd because even with the uneven costing, it still should have flowed correctly, but we fixed it and then checked the results and found the same thing. We went in and started doing more troubleshooting. Everything indicated to OSPF working correctly. Then I had the operator open a continuous ping and the results were surprising, jumping from 2 ms all the way up to 1200 ms in a matter of seconds. Something was seriously wrong.
When we would SSH into the remote router, when ping times would change we would get locked out which made troubleshooting even harder. We shut down the HCLOS link which stabilized everything and got into the other router. We removed the telnet restrictions (protocol and ACL) and then telneted into it sourcing from the local router HCLOS interface (so the session wouldn’t drop when the link went to shit again) and turned the link back on. Sure enough it started doing it again, but this time we could see what was happening. This time, we saw a logging message we hadn’t been able to see before. An already long story a little shorter, another node had the exact same HCLOS configuration (same IP address and everything) in from a previous exercise. OSPF saw an advertisement with that IP address included in the LSA and got confused and flushed the route which is why it kept bouncing all over the place which brings me to the point of the post….Knowing your baseline.
What is a Baseline?
 I have asked net techs this question many times over the years, even before I encountered this problem (this was actually the second time that I had a unit that had this problem). Every time I ask, I get the same answer (literally every single time), that it’s whatever they had been handed by General Dynamics when they were fielded or had gone through reset or whatever. That was their baseline configs. That is absolutely the incorrect answer. Baselines give us a known good configuration to fall back to and start from. Take for example the normal default username/password that is included in the configurations that are issued to each unit. One of the first things you do is to get rid of that and establish your own NETOPS username/password (you’re doing that right?). From that point on, will there ever be a time that you go back to the original? Probably not, so why is it part of your “baseline”? What we have just done is changed the baseline.
I have asked net techs this question many times over the years, even before I encountered this problem (this was actually the second time that I had a unit that had this problem). Every time I ask, I get the same answer (literally every single time), that it’s whatever they had been handed by General Dynamics when they were fielded or had gone through reset or whatever. That was their baseline configs. That is absolutely the incorrect answer. Baselines give us a known good configuration to fall back to and start from. Take for example the normal default username/password that is included in the configurations that are issued to each unit. One of the first things you do is to get rid of that and establish your own NETOPS username/password (you’re doing that right?). From that point on, will there ever be a time that you go back to the original? Probably not, so why is it part of your “baseline”? What we have just done is changed the baseline.
As we add security, or management tools, or whatever it happens to be that we know will now be included in that device’s configuration each and every time we use it, we have to update our baseline configuration to reflect that or else when we do ultimately go back to the GD baseline, we will forget to include it and wonder why something isn’t working the next time.
Start at Your Baseline
Along with establishing (and updating) our baseline configuration, it’s just as important to start each and every mission with that baseline. During the course of a FTX, NTC rotation, or deployment, you are likely to make a huge number of changes to that node to fit the specific requirements of that mission. Things like adding nodes into your TDMA mesh, installing HCLOS links or fiber connections that aren’t normally there. Just because we use them for this mission doesn’t mean that we will use them for the next one, and that is why it is critical that we always start each and every mission (for every single device) with a rebaselined system. This will start that system off on a clean slate and get rid of any configurations that will likely conflict with your new mission.
I am by no means saying that starting with your baseline configuration will prevent all of your problems, however it will do a lot to help minimize the chances of them occurring. Make sure that these configurations are easily accessible to both you and the operators. Have them saved on the management computers as well as on the flash to make reloading them easily.
NOTE: A comment from a reader mentioned baselineing workstations (management laptops, Call Managers, etc.) While it is probably not a bad idea to do that on occasion (I personally format all of my personal computers about once a year to get all of the crap off of them), that is not what I am talking about. For the purposes of this post, I mean routers, switches, firewalls, stuff like that. Baselineing a computer can take hours if not a day or more to do fully while doing a router should take about 5 minutes assuming the baseline is already saved onto the device and all you have to do is boot off of it.